Training a picasso predictor#
This notebook shows how one can train a picasso model to make predictions of gas thermodynamics from halo properties.
For a full documentation of the predictor objects and their methods, see picasso.predictors: From halo properties to gas properties.
import jax
import jax.numpy as jnp
import optax
import matplotlib.pyplot as plt
from tqdm.notebook import trange
from picasso import predictors
from picasso.test_data import halos, profs
import seaborn as sns
sns.set_style("darkgrid")
sns.set_theme("notebook")
benchmark = True
Differentiating predictions#
Since the model prediction functions described above are entirely implemented in JAX, they are fully differentiable. Let’s start by defining an untrained predictor, such that the prediction functions take as input a dict of neural network parameters \(\vartheta_{\rm net}\). We’ll mimic the “minimal” model of Kéruzoré et al. (2024), i.e. a model that takes as inputs halo mass and concentration. This means the input layer will have 2 features, and the output layer will have 8 (corresponding to the 8 parameters of the gas model). For demonstration purposes, we use an MLP with one hidden layer with 8 features.
model = predictors.PicassoPredictor(
predictors.FlaxRegMLP(
2, # Dimension of input layer
8, # Dimension of output layer
[8], # Size of hidden layers (here one hidden with eight units)
["selu", "selu", "sigmoid"], # Activation functions of ALL layers
),
"minmax", # minmax trasformation, [min, max] -> [0, 1]
"inv_minmax", # inverse minmax trasformation, [0, 1] -> [min, max]
predictors.minimal_576.args_transform_x, # minimal_576 input mins & maxs
predictors.minimal_576.args_transform_y, # minimal_576 output mins & maxs
input_names=predictors.minimal_576.input_names,
)
flax allows us to initialize \(\vartheta_{\rm net}\) easily:
theta_nn = model.mlp.init(jax.random.PRNGKey(44), jnp.ones(model.mlp.X_DIM))
print(f"{theta_nn=}")
theta_nn={'params': {'input': {'kernel': Array([[-0.28656918, -0.8363784 ],
[-0.00913648, -0.15502064]], dtype=float32), 'bias': Array([0., 0.], dtype=float32)}, 'dense1': {'kernel': Array([[ 0.48479113, 0.2919482 , 0.04451464, -0.65522856, 0.01721897,
-0.40018314, -1.0726198 , 1.1703769 ],
[ 0.13510484, -0.30340514, 0.6889926 , -0.03902151, 0.58330196,
-0.10688772, -0.9215972 , 0.6594059 ]], dtype=float32), 'bias': Array([0., 0., 0., 0., 0., 0., 0., 0.], dtype=float32)}, 'output': {'kernel': Array([[-0.46607548, 0.71506864, 0.04893673, -0.13021016, -0.42088723,
0.11978187, 0.09521458, -0.51279926],
[-0.596398 , -0.49825567, -0.12462255, 0.4810683 , -0.10093934,
-0.13432854, -0.17744671, -0.07458336],
[ 0.13238773, -0.22845873, -0.19174618, 0.75797164, 0.02974986,
-0.36638138, 0.01422992, 0.13200618],
[-0.5331755 , -0.42876288, 0.77523994, 0.0504402 , 0.5301908 ,
-0.80165267, -0.38466203, 0.06529935],
[ 0.2736491 , 0.22497854, 0.6703771 , -0.2505522 , -0.53149974,
-0.35776165, 0.23287444, -0.20596929],
[ 0.07715659, 0.20024352, -0.39178902, -0.06374976, -0.42675093,
-0.49857923, -0.22317016, 0.5624913 ],
[ 0.1088736 , -0.18718773, 0.22244939, 0.42377624, 0.01381926,
-0.10177649, 0.1507899 , 0.08696614],
[ 0.30764598, -0.01823961, -0.2243769 , -0.73573065, -0.3309998 ,
-0.19017354, -0.21619093, -0.3309007 ]], dtype=float32), 'bias': Array([0., 0., 0., 0., 0., 0., 0., 0.], dtype=float32)}}}
Now, we can write a loss function. For example, let’s write a mean square error function that compares the predictions of the gas thermodynamics with the halo properties found in the hydrodynamic simulations. For illustration purposes, we use a very small set of 7 halos for which we have all inputs and true thermodynamic profiles:
phi = profs["phi"]
r_R500c = profs["r_R500"]
logM200c = halos["log M200"]
c200c = jnp.array(halos["c200"])
theta_halo = jnp.array([logM200c, c200c]).T
target = jnp.array(
[
profs["rho_g"],
profs["P_tot"],
profs["P_tot"] * (1 - profs["f_nt"]),
profs["f_nt"],
]
)
def loss_fn_predict_parameters(theta_nn):
preds = jnp.array(
model.predict_gas_model(
theta_halo, phi, r_R500c, r_R500c / 2, theta_nn
)
)
loss = jnp.mean((preds - target) ** 2)
return loss
We can use jax.value_and_grad to compute, for an input \(\vartheta_{\rm net}\), the value of the loss function and its gradients with respect to the components of \(\vartheta_{\rm net}\):
loss_fn_and_grads = jax.jit(jax.value_and_grad(loss_fn_predict_parameters))
loss, grads = loss_fn_and_grads(theta_nn)
print(f"{loss=}")
print(f"{grads=}")
loss=Array(21196.256, dtype=float32)
grads={'params': {'dense1': {'bias': Array([-31702.564 , -68422.11 , -14758.855 , -75493.875 , 48815.46 ,
16125.58 , -2643.0715, 52633.625 ], dtype=float32), 'kernel': Array([[ 6.8014126, -271.3709 , -103.63039 , -541.9973 ,
-113.194664 , 120.75635 , -100.38055 , 169.08105 ],
[ 1005.2929 , 1274.2083 , 154.1843 , 640.9485 ,
-1871.2783 , -123.28124 , -219.17368 , -1138.1871 ]], dtype=float32)}, 'input': {'bias': Array([79232.14, 80954.19], dtype=float32), 'kernel': Array([[-2427.6716, -1470.5756],
[17470.34 , 18220.209 ]], dtype=float32)}, 'output': {'bias': Array([ 8.4009773e+04, 1.8406162e+03, 1.0583838e+04, -2.9046648e+04,
-1.1800704e+04, -8.6387920e+00, -2.8432214e-01, 6.7295194e-01], dtype=float32), 'kernel': Array([[-5.3921497e+02, -6.4272017e+00, -2.1364821e+02, 2.8723917e+00,
1.9457185e+02, 6.0709886e-02, -6.9429498e-04, 3.6108531e-03],
[ 6.4933612e+02, 1.1891390e+01, 1.4772592e+02, -1.4327725e+02,
-1.4550081e+02, -6.9982663e-02, -9.5332955e-04, 1.5200091e-03],
[-2.1927991e+03, -3.6228630e+01, -6.0729242e+02, 3.4857336e+02,
5.8019232e+02, 2.4093169e-01, 1.1651973e-03, 8.6328667e-04],
[-5.5064349e+02, -1.5332279e+01, 1.8389397e+01, 3.0135861e+02,
5.9049797e+00, 5.3614292e-02, 3.3379367e-03, -9.1710119e-03],
[-1.8913945e+03, -3.1344032e+01, -5.2055249e+02, 3.0433713e+02,
4.9764523e+02, 2.0748344e-01, 1.1045656e-03, 5.3984474e-04],
[-2.1747220e+02, -7.7362156e+00, 5.3205185e+01, 1.7658067e+02,
-3.5224613e+01, 1.9362107e-02, 2.1242574e-03, -6.1402442e-03],
[ 3.5367377e+02, -7.6641817e+00, 4.6671155e+02, 4.0606613e+02,
-3.9494821e+02, -5.3275295e-02, 6.2452597e-03, -2.0334167e-02],
[-2.0366202e+03, -2.8016426e+01, -7.1862018e+02, 1.3037570e+02,
6.6536487e+02, 2.3001339e-01, -1.7958788e-03, 9.3031405e-03]], dtype=float32)}}}
This loss function can then be optimized using, e.g., optax (See the optax docs here, in particular the tutorial to optimize the parameters of a flax model here):
optimizer = optax.adam(1e-2)
opt_state = optimizer.init(theta_nn)
@jax.jit
def train_step(theta_nn, opt_state):
lt, grads = loss_fn_and_grads(theta_nn)
updates, opt_state = optimizer.update(grads, opt_state, theta_nn)
theta_nn = optax.apply_updates(theta_nn, updates)
return theta_nn, opt_state, lt
all_lt, all_lv = [], []
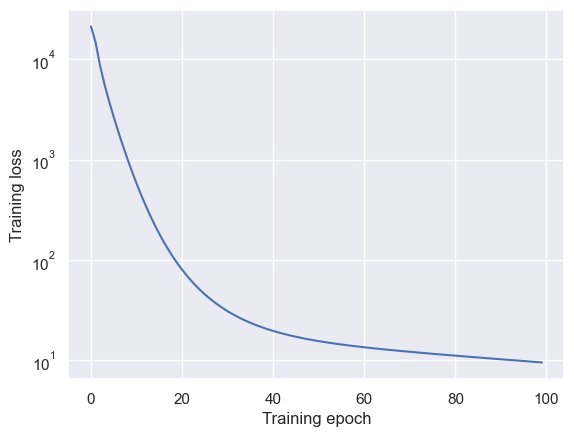
for i in trange(100):
theta_nn, opt_state, lt = train_step(theta_nn, opt_state)
all_lt.append(lt)
all_lt = jnp.array(all_lt)
(note that you can accelerate this training loop using, e.g., jax.lax.scan)
fig, ax = plt.subplots()
ax.plot(all_lt)
ax.set_yscale("log")
ax.set_xlabel("Training epoch")
ax.set_ylabel("Training loss")
Text(0, 0.5, 'Training loss')